Update 3 May 2020: after a bit of a requests bill spike, I had another look at rclone’s options and the S3 storage classes. You can now directly create backup objects with Intelligent Tiering by setting the backend storage_class, which in theory should be much cheaper for frequent backups. I’ll report back on whether it really is!
Update 10 Apr 2021: I think the answer to this is… maybe?! Costs are very slightly lower on average but this also coincides with several months with fewer backups. One thing that is noticeable so far is that the variation is less – I’ve not hit such a big subsequent cost spike again. But this could be down to my behaviour as much as the tiered pricing’s, and of course your mileage will certainly vary!
I recently tried out a new remote backup approach.
Whether you consider it a success will probably depend on your quantity of files, and how much money you have lying around for month #1.
Previous efforts
I’ve been looking for my optimal off-site backup system for years now. I even spent some time building a cross-platform GUI wrapping rsync, with a view to offering a managed service bundled with storage like rsync.net (which I’ve also used happily before). The idea was to benefit from buying server space at scale, and lower the barrier to making backups this way. This might have been a worthwhile endeavour several years ago, but after seeing the progress of similar front ends and the plummeting cost of large scale cloud cold storage, I’ve now decided it’s not a great solo project!
To the cloud!
Other clouds are available, but up front AWS appeared to have the cheapest cold storage options out there, so that’s where I started. Somewhat confusingly, there are two only tangentially-related Amazon entities carrying this name – the standalone Glacier service, and the Glacier S3 storage class.
I tried out a cross-platform desktop GUI app intending to use it for Glacier-the-service on macOS, before realising it only supported that mode on Windows. I also tried it with S3 using my own transition-to-Glacier lifecycle rules, but found it very unreliable.
However by this point I was more or less sold on using the much more widely supported S3 protocol with some tool or other, and saving storage costs by transitioning to the Glacier storage class with rules I could configure and understand myself. This may cost more than Glacier-the-service, but it means wider compatibility and allows AWS’s versioning system to do its job, without building in extra layers of backup tool-specific abstraction for this purpose.
After looking at a couple more tools I decided to try rclone, along with manually-configured Glacier transitions.
What’s the setup?
So what do my backups actually look like?
S3 lifecycle transitions
I’m sure there’s a nicer way to get this configured for all your buckets, but I did it manually in the UI for each one. This wasn’t one of the properties copied over if you use one bucket as a template for another.
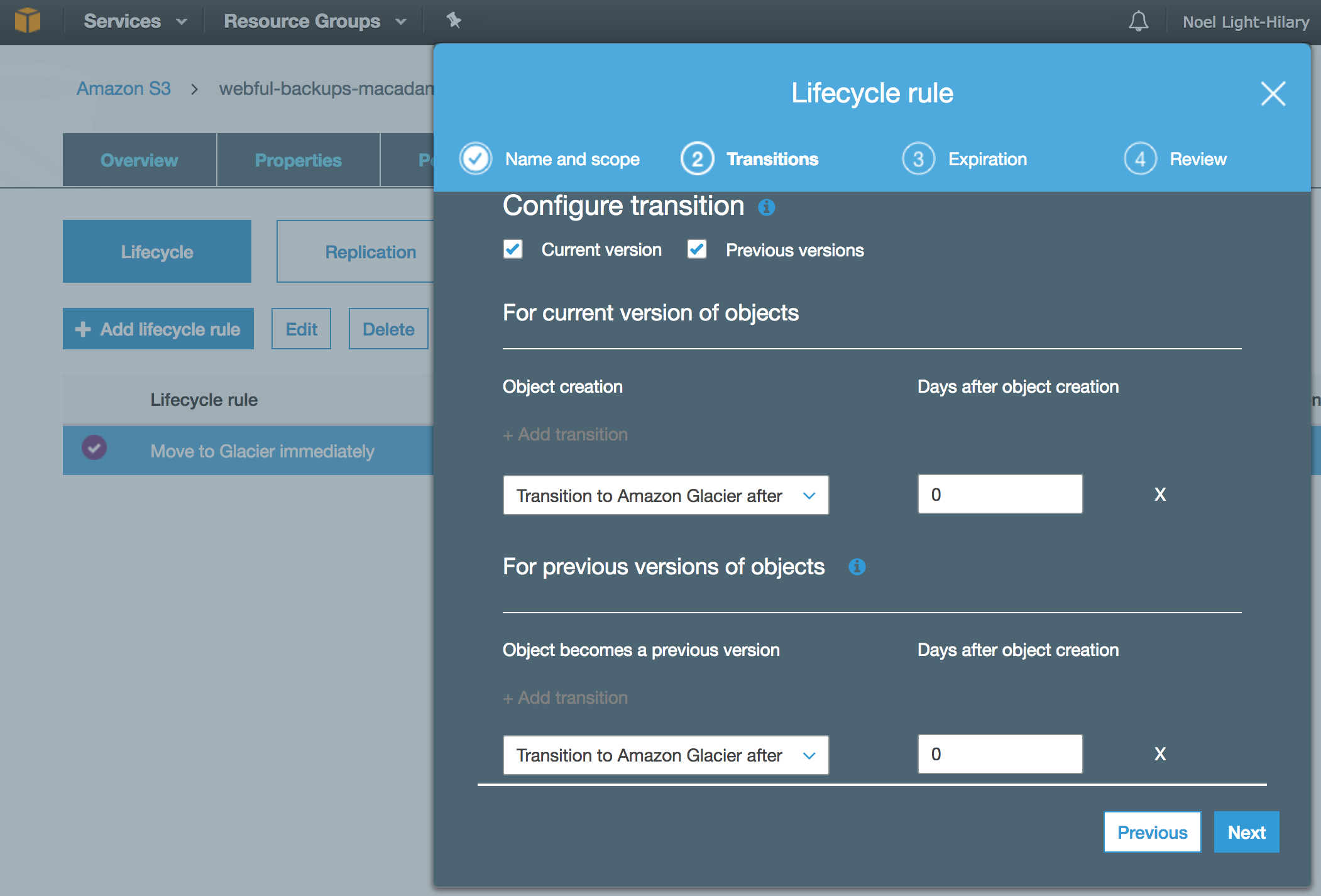
rclone options
My main source of errors with rclone after getting the first sync right was from modification times being amended on files with no other changes. S3 won’t let you do that once an object has transitioned to Glacier class. In these cases I don’t care about mod times, so for me no-update-modtime was the perfect option.
I have 4 backups going to separate buckets, and a typical one now looks like
/usr/local/bin/rclone sync --quiet --no-update-modtime --fast-list /Users/noel/files/Docs s3-backup:my-docs-bucket-123
I trigger this with a terribly old-fashioned cron job with my email set in the MAILTO. And because it’s got quiet mode on, I get an email only if it hits an error. I also use flock to make sure the same job’s not running twice at once.
$£€!
After setting up all my jobs initially, I was a little surprised to receive a billing alert much, much sooner than expected, having set a limit which I thought I might approach towards the end of the month.
I knew that retrieving Glacier data was relatively slow and expensive – it’s designed to be accessed rarely. The main thing I missed – and not a crazy charge if you’re expecting it – was this:
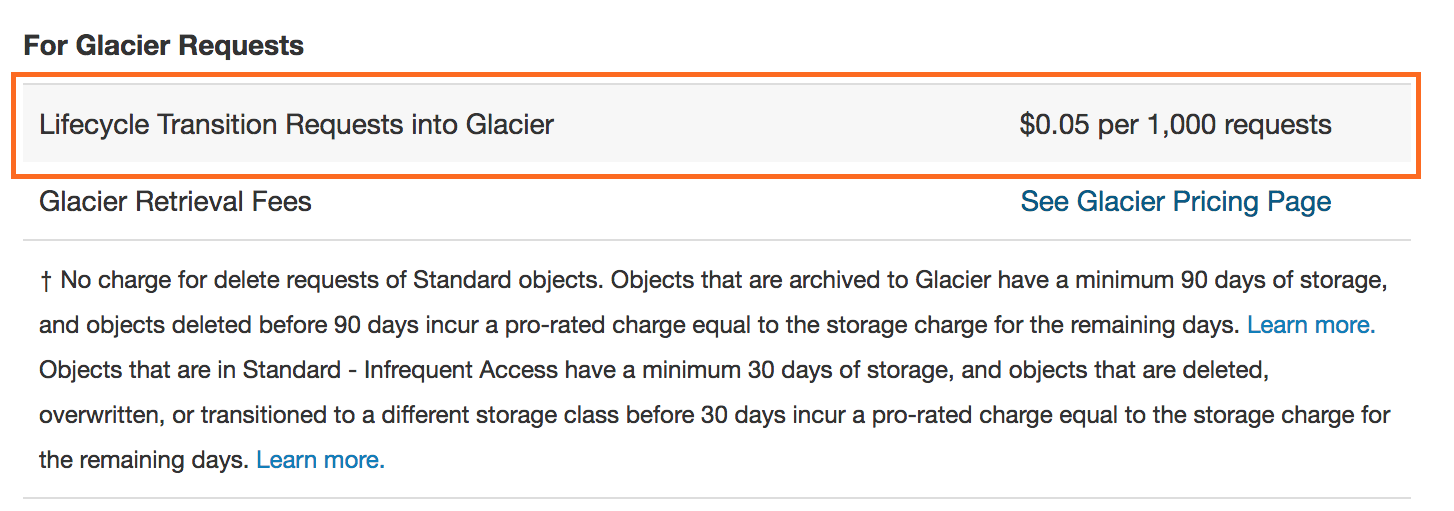
Racking up a little over 2 million new backed up objects in my initial sync, this added $114 USD to my month’s costs – pretty much fully explaining the order of magnitude difference vs. my very rough cost estimate.
I think the main take-away here is to start small if you don’t yet fully understand the costs of this stuff. For all that the big cloud providers like to diss each other’s pricing models, none of them are particularly simple and there is always a chance you’ll miss stuff!
The glorious future
The good news is that now my files are there – and since most of them don’t change very often – this looks like a totally viable system cost-wise if you ignore the initial outlay. Which I might as well as it’s not coming back. 🙂
This may look like classic sunk costs rationalisation, but the average rate of change on these files is really low, and on a day with no changes I’m paying 4 US cents to keep my backups on Amazon’s Glacier tapes. Even with bigger changes, monthly costs look set to be dramatically lower than the £43 GBP I was paying to hire a dedicated server with lots of storage. (Even that price was only offered, back in the day, after putting down a large initial up-front payment.)
One point to keep in mind is that rclone’s GET requests to check the status of files actually make up about half the cost of my backups now, in a quiet month with few changes (the last of which cost me £9). So the frequency of your backups could make a real difference to the cost if you have a large number of files being checked, even if they change rarely. This is quite a big difference from a traditional rsync-to-server setup.
But while it looks like the price variation will be greater, I’ve found a backup frequency that works for me and should prove much cheaper for my use on average. I’m looking forward to retiring my old backup server very soon!